开发需要知道的CPU底层知识学习记录
CPU的作用:
取指令,取数据,做运算,然后将运算结果写入内存,线程是CPU执行的最小单元
CPU的主要组成:
指令计数器PC:
作用:保存下一跳指令的地址,CPU在运行的时候会根据指令寄存器中保存的地址从内存中获取数据,获取完后回保存到CPU的寄存器中。
寄存器 Registers:
作用:用来保存从内存中读取过来的数据
运算单元ALU:
作用:根据根据寄存器中保存的数据做运算,算完后再写入到内存中
高速缓存 Cache:
作用:用来缓存内存中的数据,避免直接从内存中获取,提升CPU的运算周期效率。
一台计算机CPU访问数据共享范围:
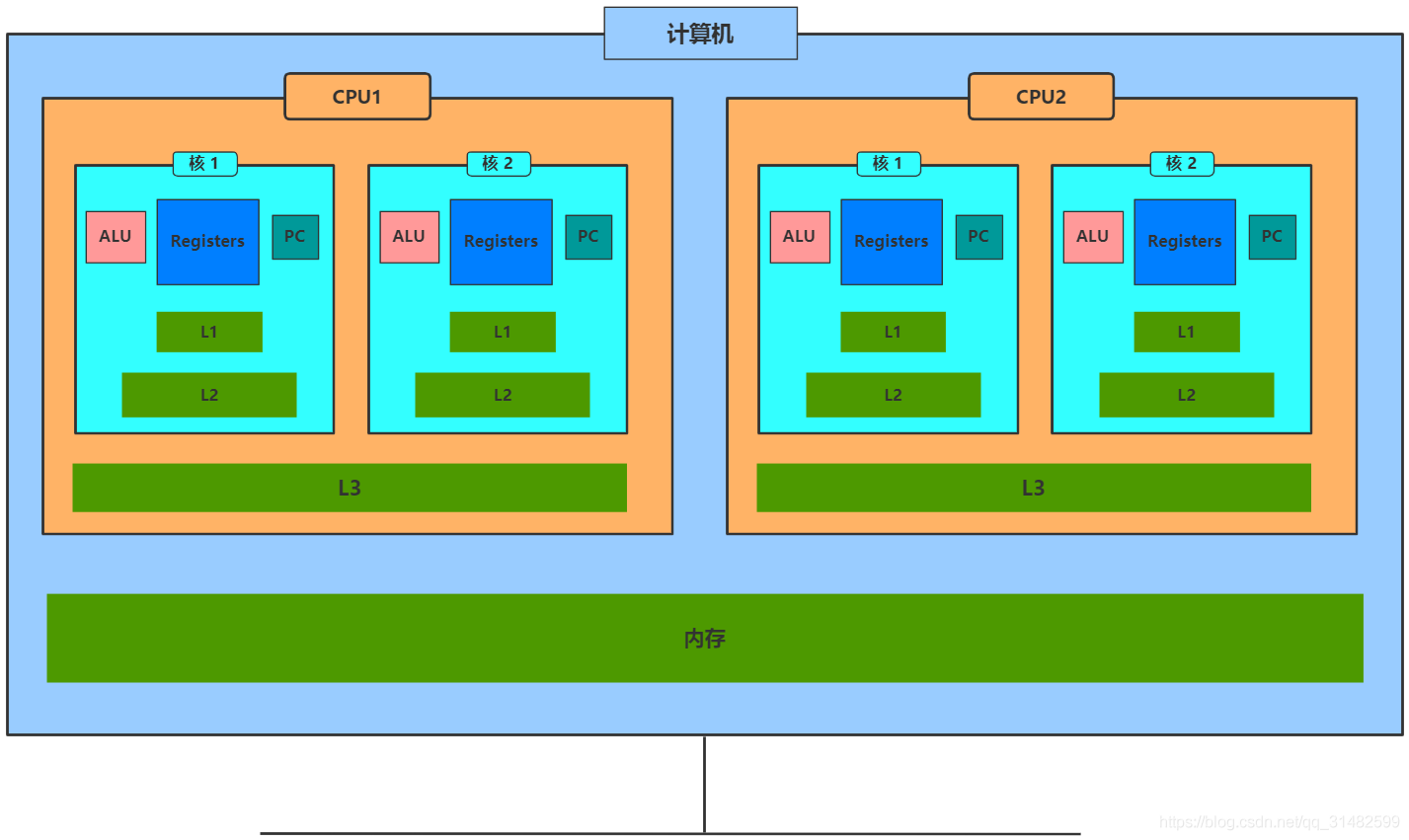
说明
- 一台计算机的多块CPU可以共享内存
- 每个CPU的的多核公用一个三级别缓存
- 每一个核都有一级缓存、二级缓存、Registers、ALU、PC
CPU获取数据的时间周期对比
下图数据来源网络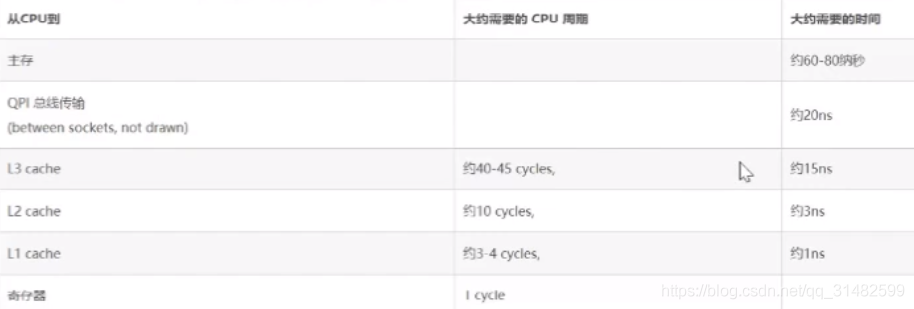
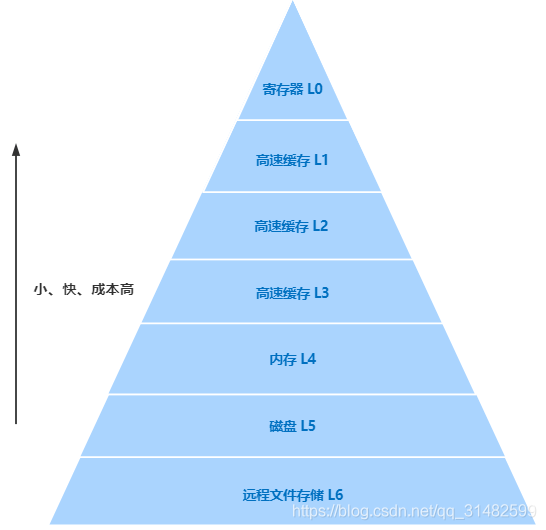
CPU执行单线程:
当前线程执行到一半的时候,如果要让出CPU时间片,会将当前执行线程对应的数据和当前执行状态(指令执行行数、指令执行位置、指令执行数据等)保存到内存中,然后将CPU时间片让给下一个要执行的线程。当原来执行到一半的线程再次抢到CPU时间片的时候,会根据原来执行了一半的线程保存的线程执行状态恢复数据到CPU(恢复现场),接着原来指令执行位置继续向下执行。超线程:
CPU运算最快的单元是ALU
单核双线程、四核八线程 ,双核四线程 一类
为了提升ALU的计算周期利用率,一个ALU 可以对应 两组 寄存器+指令计数器,这样一个核就可以装两个线程,ALU切换计算两组寄存器+指令计数器中的指令,这样即提升了计算周期,也可以很大程度省区切换线程恢复数据的周期。
CPU 内存:
CPU中内存可见:通过缓存一致性协议同步数据
CPU内存行(Cache line):CPU从内存中读取数据的方式 一次读一堆, 一块一块的读,每一块叫缓存行(Cache line) 一般:一块=64字节
CPU在计算的时候会根据指令先从L1中找,找不到再从L2中,知道内存中找,从内存中找到后会将数据相关的一整块(一个Cache line)依次读到L3、L2、L1,然后再做计算
同一CPU中,多核之间可能同时缓存同一缓存块的数据,如果核1中修改的数据有volatile 关键字修饰,对核2中线程必须要可见,多核之间为了确保不同核中 L1 和 L2 中缓存的Cache line 中的数据一致性,采用的是缓存一致性协议。有些无法缓存的数据或者跨多个缓存
缓存一致性协议:
缓存一致性协议有很多种,MESI只是其中一种,取决于不同的CPU
MESI 是指缓存行 Cache line 的四种状态
Modified 被修改了
Exclusive 独享
Shared 共享 大家都去读 并不修改
Invalid 失效
说明:如果一个缓存行 Cache line 中缓存了一堆数据 有x ,y
当核1 中 x 修改后 核1中的 Cache line 的状态变为 Modified,并写入内存, 这时会通过 两核之间的联系通知给核2,告诉核2 该Cacheline 已经被修改了,之后 核2中的 Cache line 的状态 变成 Invalid ,即表示该缓存行已失效,应重新从内存中读取
结论:
两个线程在同时修改两个数据时,如果这两个数据在同一个缓存块中,效率要低于两个数据在不同缓存块的情况,因为同一缓存中的数据在被更新的时候会通过缓存锁等待相互更新完毕后再同步数据,而不同缓存中不需要通知其它缓存行数据已经过期,所以速度快。
证明:
1 | |
CPU 乱序执行
目的是为了提升CPU执行效率
说明:
有两条指令 A B,先执行A指令,A指令可能由于从内存中读取数据,执行比较慢,这时候CPU是空闲的,为了提升CUP的效率,会查看b指令是不是和A指令有依赖关系 如 B = A +1,如果没有依赖关系 会先去执行B指令