HashMap源码(一)—— 数据结构put存储过程介绍
HashMap 数据结构
- Jdk1.8之前:数组+链表
- Jdk 1.8之后 数组+链表+红黑书
- 链表长度大于8后并且数组长度 大于64 链表结构转化成红黑树结构
为什么jdk8之后要用红黑树
因为链表插入快,查询慢,当链表太长时,
相当于 node.next.next.next.next.next.next.next.next …… = new Node(xx)
其中next就相当于插入,而红黑数可以通过左旋右旋的方式减少查找深度
Hash算法
Hash算法也叫散列算法,就是把任意长度值(Key)通过散列算法变幻成固定长度的key值,通过这个地址进行访问的数据结构。它通过把关键码值映射到表中的一个位置来访问记录,达到加快查找的速度。这个映射函数叫散列函数,存放记录的数组叫散列表。
put方法图解
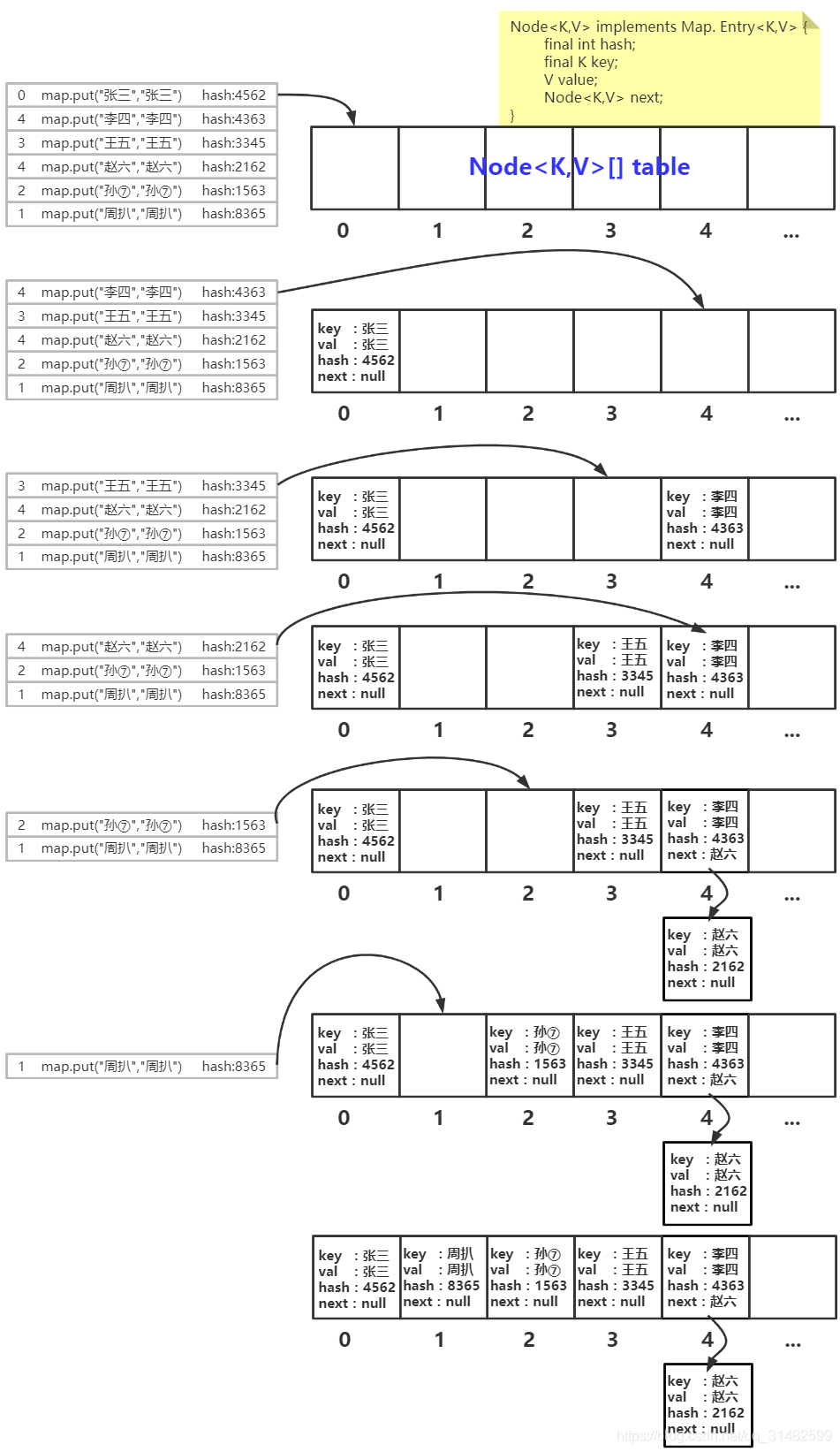
链表存储说明
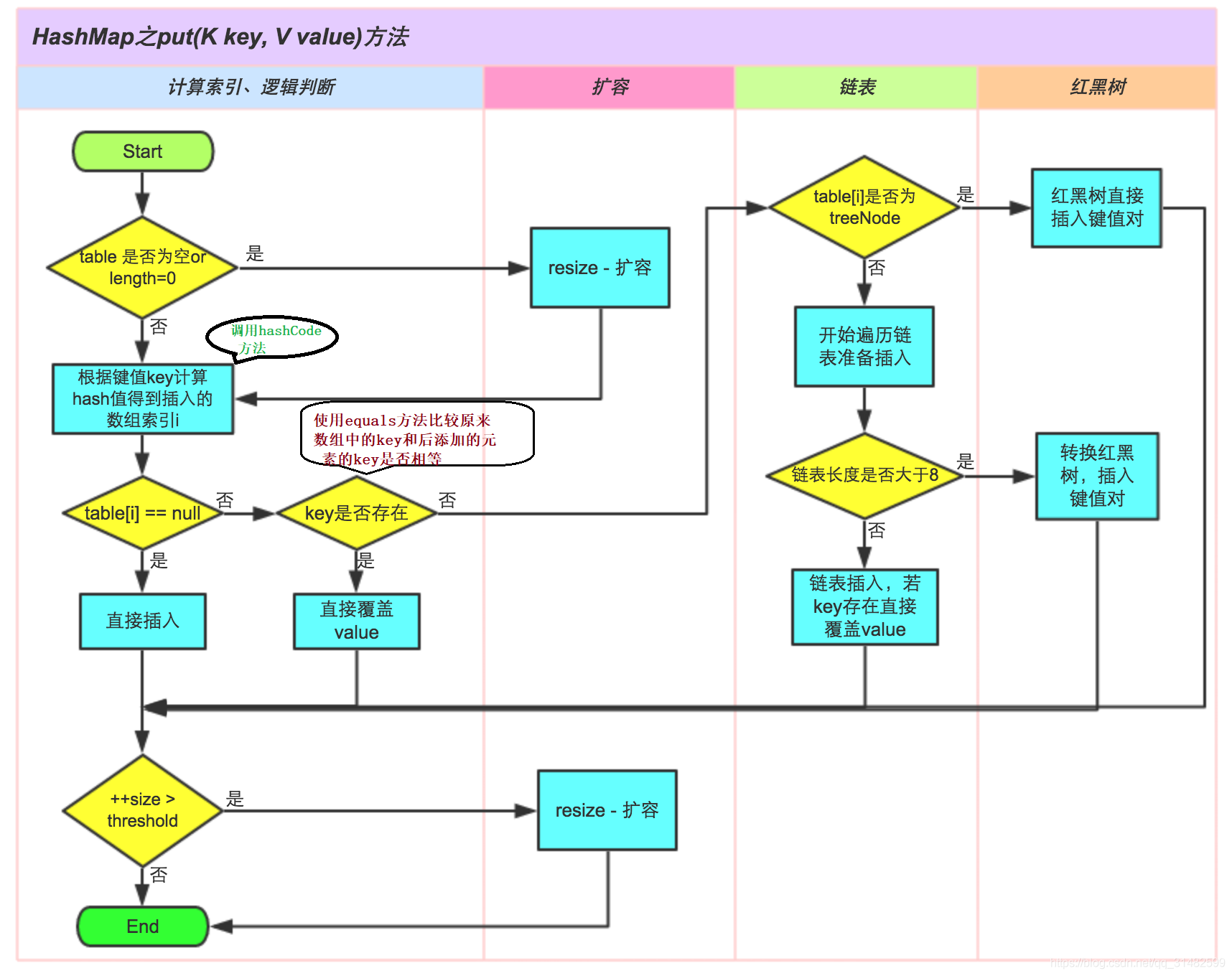
以下代码是hashmap在put数据时摘抄的一部分逻辑
1 | |
HashMap map = new HashMap<>() 的执行过程
jdk8之前:
构造方法中创建了一个长度是16的Entry[] table 用来存储键值对数据。
jdk8之后:
不在构造方法中创建,在第一次put方法时创建的 Node[] table 来保存数据。
调用put 时保存数据的过程
put的数据在数组中的位置是根据 key 调用String类中的重写之后的hashCode()方法计算出的值,然后结合数组长度结合某种算法计算出对应的index值来确定数组中的位置。
如果之后put的key计算出的索引和原来的一致,此时会比较两个hash值是否相等,如果不想等,则在此索引位置对应的空间划一个节点来保存该数据。如果hash值相等,则发生hash碰撞,这时会调用String中的equals方法比较两个值得内容是否相等,如果比较的内容相等,则覆盖原来的,如果不想等,继续向下和其它的数据key进行比较,如果都不想等,则划出一个节点存储数据
总结: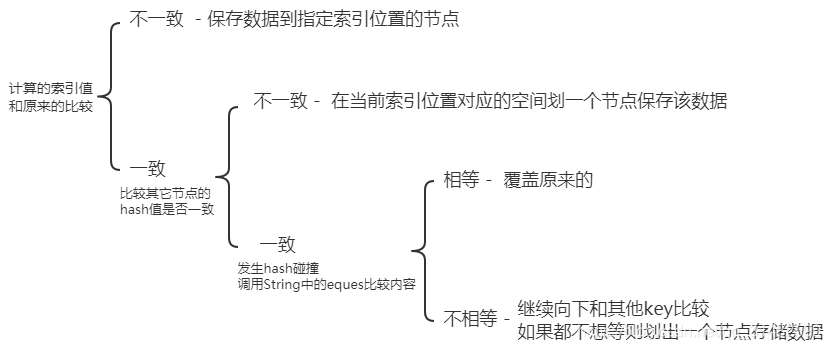
map.put存储图解 (图片来自网络)
HashMap源码(一)—— 数据结构put存储过程介绍
http://yoursite.com/post/5da25537.html/